基于金融大模型的智能投行建设研究(4)
时间:2024-02-20 22:10 来源:网络整理 作者:墨客科技 点击:次
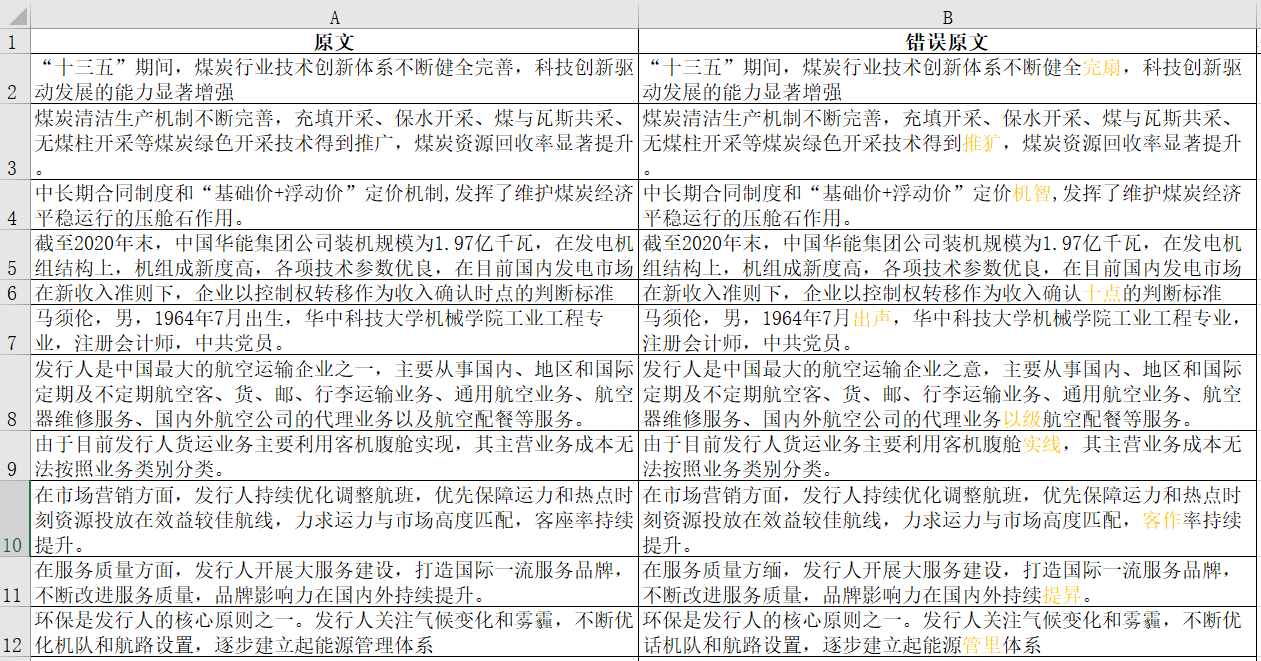
总而言之,大模型在制式文档方面会起到非常大的作用,基本上可以让机器来全部生成。但在非制式文档方面,更多是起到抽取信息填充的作用,或辅助生成分析话术供人工修正。 (三)基于大模型智能核查 证券投行业务包括IPO、债权融资、并购重组、资产证券化、股权融资、新三板挂牌等,每个业务条线都涵盖大量的文书工作并受到强监管。特别是对非结构的数据处理和整合,这部分工作是影响各条线业务执行效率和效益的关键因素。比如投行业务中的IPO工作,会涉及大量底稿工作,包括招股说明书、发行公告、审计报告、本次发行申请及授权文件、发行保荐书等文书对象的编排制作,还是会涉及银行流水核查、尽职调查、财务反粉饰等审查环节。借助了金融大模型能力实现智能核查,则重构和优化业务流程,缩短流程周期,提升人效。智能核查内容包括但不限于如下: 篇章目录格式 文书规范(含错别字/敏感词等) 格式(含日期格式、数值格式等) 财务数据审查(含多文本交叉核验) 非财务数据审查(股权结构,董监高等) 信披审查 主体评级一致性 监管法律规范要求等 实际上,大模型更多的工作在于底稿数据提取(包括审计报告、财务报告、上市保荐书、公司章程、资质证明、专利证书等),核查规则设计更多依赖于规则引擎。大模型能够极大提升对底稿数据、尽调数据等相关指标的提取,再输送给规则引擎,从而保障了智能核查的质量。从这个层面来看,大模型要做的工作和智能抽取无异。 还有一部分就是错别字和语义纠错层面,即文书规范层面。这方面大模型具备无可比拟的优势,因为它学习了大量“通才”知识,又专修了金融领域的“专才”知识,知识面非常广,能够更准确的判断出申报材料中是否存在错别字或语义不顺等情况。下面进行测试说明: 1.错误类型 本次研究包括如下错误类型: 成语检查 连字检查 金额检查(大小写) 错别字检查 缺词检查 敏感词检查 2.测试集 本次测试集约1395条,包含了如上所罗列的错误类型。部分样例间下图。“原文”一列为正确内容,“错误原文”一列为包含错误的内容,并用黄色高亮区别。
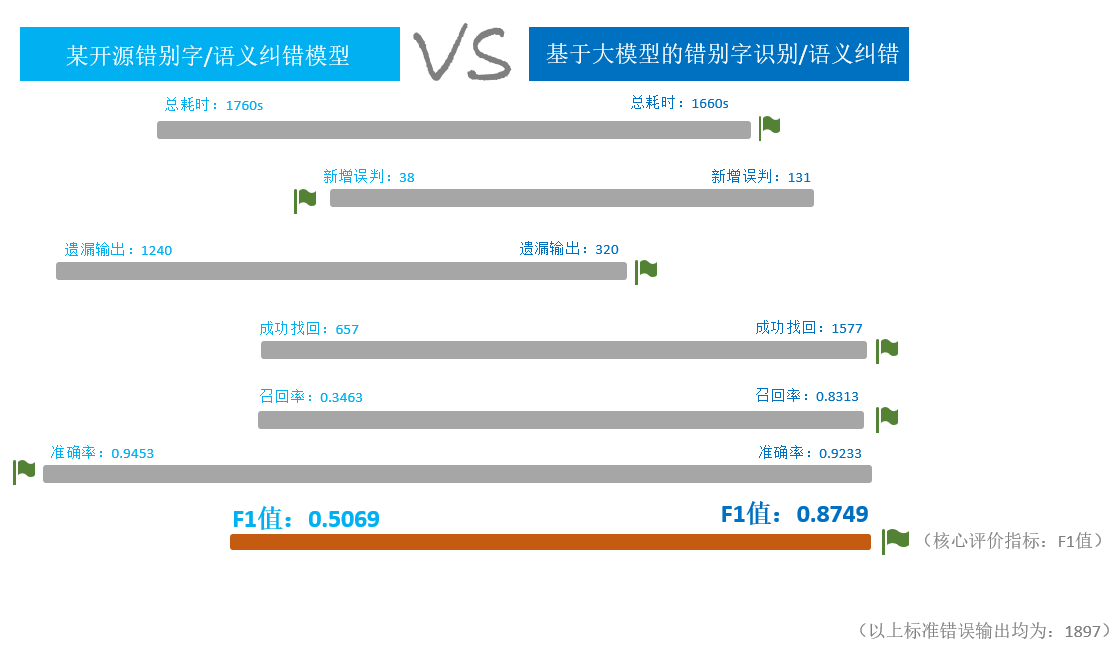
图10:错别字核语义记错-测试样例集 3.测试结果 某开源错别字/语义纠错模型VS基于大模型的错别字识别/语义纠错
图11:传统语义纠错模型和基于大模型的语义纠错模型效果比较 对比两者的测试结果,可以看出基于大模型测试的F1值大幅度领先,其在文书规范核查层面有非常不错的成效。 五、总结与展望 未来,广发证券将围绕金融科技发展战略,持续打造投行数智化体系,探索金融大模型在投行领域的应用,以金融大模型为基座全面升级智能投行系统,构建智能抽取、智能生成、智能核查等能力,赋能投行文档智能一体化处理方案建设。有效支撑投行全业务品种、全生命周期的数智化管理,提升在注册制下的投行执业质量、风险控制水平、信息披露质量。 (责任编辑:admin) |