基于金融大模型的智能投行建设研究(3)
时间:2024-02-20 22:10 来源:网络整理 作者:墨客科技 点击:次
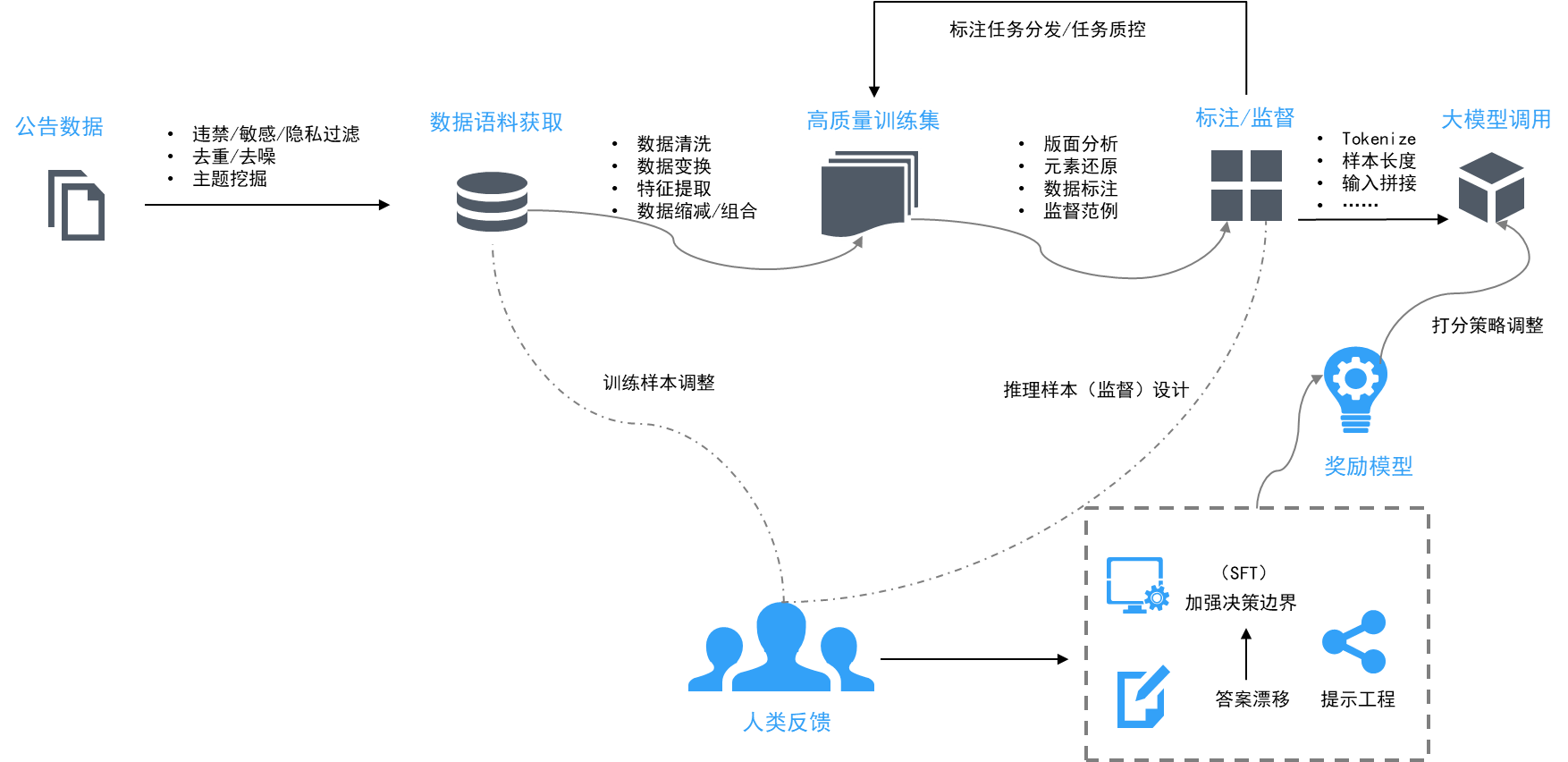
基于大模型底座建设投行文档智能抽取、智能生成、智能核查能力。智能抽取能力构建投行数据底座,提供统一的结构化数据来源,支撑投行业务文档智能生成和智能核查。打造从数据到投行业务文档生成、核查的全生命周期工具链平台。 (一)基于大模型智能抽取 本次场景研究主要是基于投行领域常见的公告数据进行提取,从公告中提取董事会决议。在此之前需要对模型进行微调,让其获得对应“语感”。其这个过程中要做大量的语料工程工作,其大体流程如下:
图5:语料工程设计 其中比较核心的就是在tokenize时,做好向量分割、向量嵌入和计算。此外存在公告token超出的模型输入限定的情况,因此还要做好token拼接工作,保障大模型能够正确理解同一份公告的上下文语义。 接下可面向下游提取任务设计提示工程,让大模型能够正确提取相关信息,以公开数据《松霖科技:关于第三届董事会第一次会议决议公告》为例: 1.输入样例: 《松霖科技:关于第三届董事会第一次会议决议公告》 2.输出要求: { "内容1": {"证券简称": "string","证券代码": "string","届次": "string","公司名称": "string","公告日期": "string","公告名称": "string"}, "内容2": {"会议召开时间": "string","会议召开方式": "string"}, "内容3": {"通过议案的名称": [{"会议名称": "string"}]}, "内容4": {"未通过议案的名称":"string"} } 3.提示工程 提示示例: 【你是一个提取结构化信息的机器人,你的目标是匹配输入与输出中每个描述相符合的信息,并按JSON格式输出结构化提取信息。在提取信息时,不要添加任何没有出现在输出中显示的属性。除了提取的信息外,不要输出任何内容,不要添加任何澄清信息,不要添加任何不在模式中的字段。如果文本包含架构中未出现的属性,请忽略它们。】 4.样本集评估
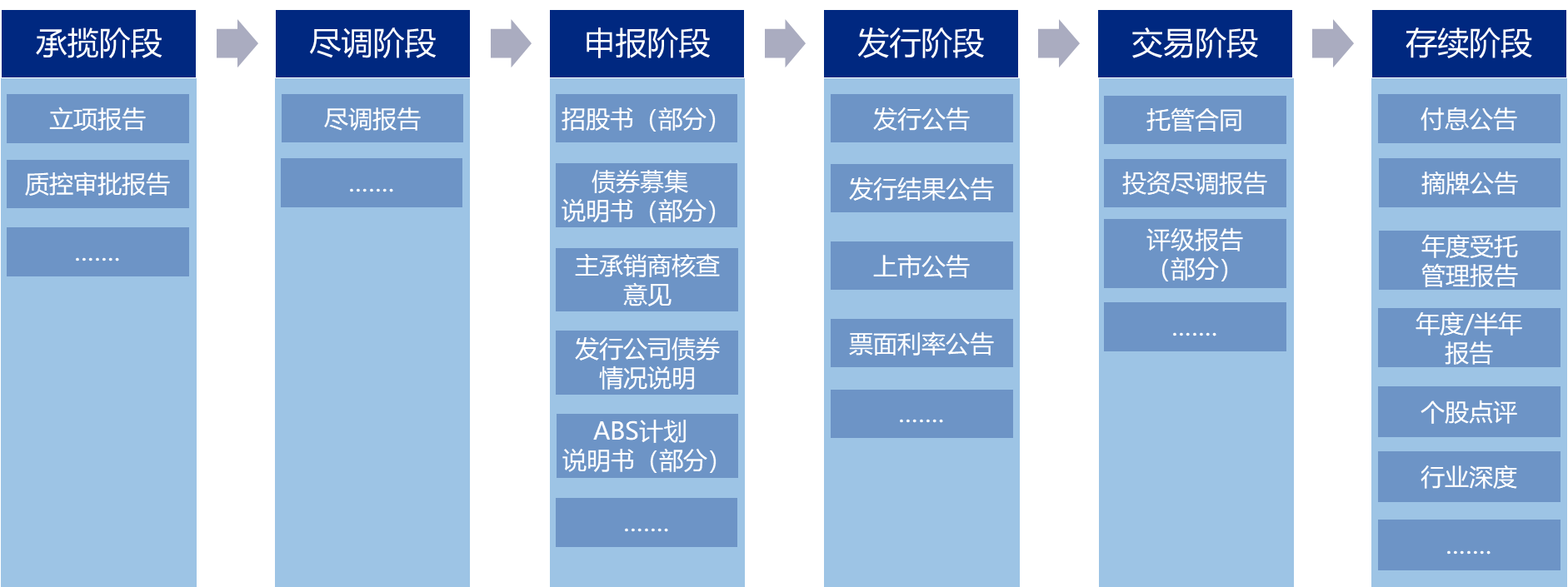
图6:部分样本提取结果 图6为部分样本的提取测试结果,其提取准确率达到了95%。实际上,本次测试样本为200份公告,整体准确率达到85.6%以上。相比于传统技术,标注工作量极大地减少,且能在短时间内就提升模型精度,可落地性非常好。 (二)基于大模型智能撰写 除了抽取任务,大模型还可以用在撰写生成的场景。实际上,投行业务涉及非常繁重的申报材料编制工作,包括债券募集说明书自动撰写、ABS计划说明书撰写、公告撰写等。在大模型出来之前,市面上也有智能撰写相关的产品,但对整个证券行业落地还是非常的少。究其原因,申报材料本身内容存在主观性,且编写业务逻辑相对复杂,因此大模型在此方面的应用还是非常少。基于审慎原则,更多是先把撰写生成能力用于制式文档或非制式文档的部分内容生成。如下为部分撰写生成场景:
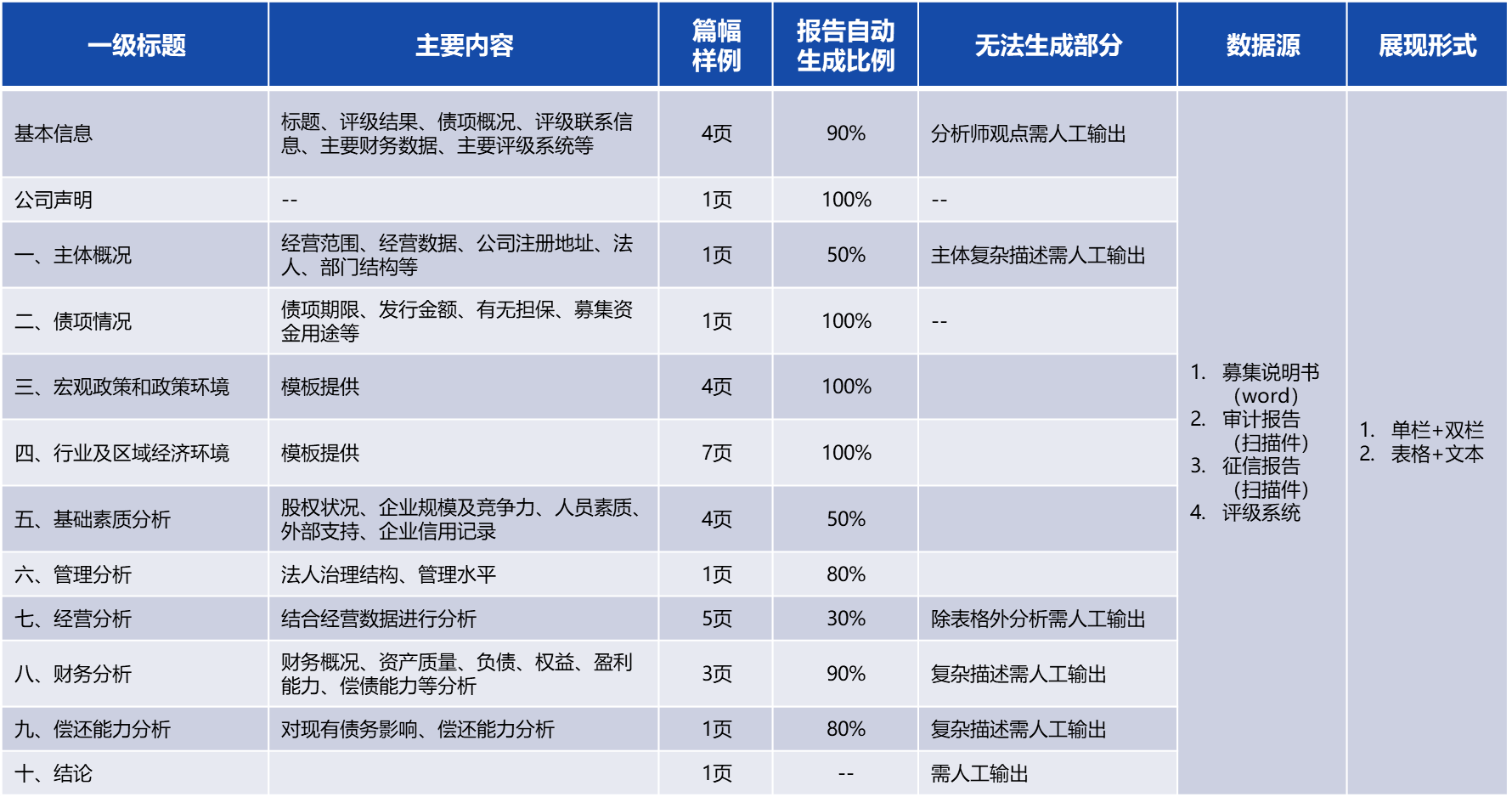
图7:投行撰写生成场景 下面以债项评级报告自动撰写为例进行介绍。 1.撰写内容分析 对评级报告而言,其涉及主观部分和客观部分,智能生成主要是集中的客观部分。如下图所示:
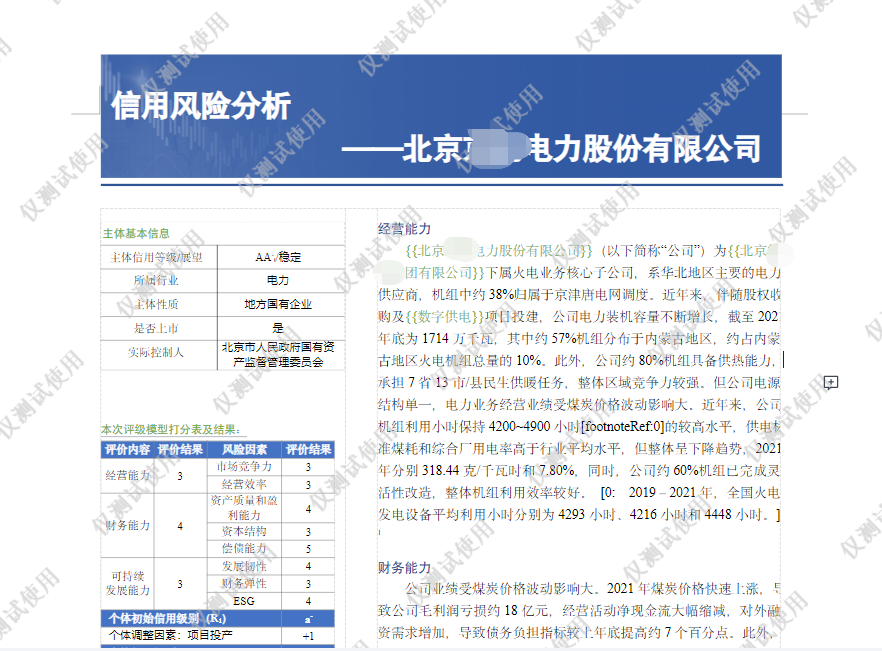
图8:评级报告撰写内容分析 可以看到像公司声明、债项情况、行业及区域经济环境等章节内容,模板化程度高,可全部交给大模型生成;而像主体概况、经营分析等章节内容相对复杂,依赖人工分析才能输出,因此大模型部分帮助。这里面还有一个核心的工作就是:大模型需要从募集说明书、审计报告、征信报告等非结构化文档提取相关财务、征信评级、债项期限等填充到评级报告。 2.生成样例
图9:评级报告生成样例 如上所示,大模型基于抽取能力,自动在评级报告中对应位置填充相关信息(以双花括号和绿色来标记),左侧的“主体基本信息”、“本次评级模型打分表及结果”也从相关文档或评级系统同步过来。至于经营分析、主体概况等依赖人工总结的,则还是由人工来处理。 (责任编辑:admin) |