QuickNAT:HighPerformanceNATSystemonCommodityPlatforms(4)
时间:2023-05-04 15:19 来源:网络整理 作者:墨客科技 点击:次
Quick NAT system installs two new connection records for this flow and its reply flow. As Figure 9 shows, one record is the original connection record and another record is the reply connection record. The reply connection record is pre-installed to be used for dealing with the reply flow. Each connection record contains initial tuple and revised tuple to record the NAT mapping of the flow. In addition, each connection record has a timestamp field, which is refreshed when a packet matches this connection record. A dedicated core is used to delete timeout records and reclaim the IP/Port periodically.
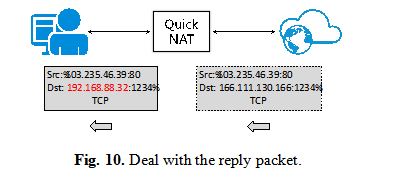
6)Deal with the reply packet In Figure 10, the website server sends out the response after receiving the request from user. Due to the pre-installed reply connection record, Quick NAT system recognizes this response packet and then revises its destination IP. After revising the tuple, it sends out the modified packet.
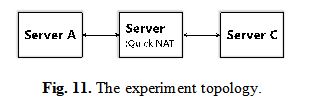
3.3 Lock-free Sharing Among CPU Cores As it becomes more difficult to increase clock speed on single-core CPU, multi-core processors have been pursued to improve overall processing performance. In order to effectively utilize multi-core processors, we leverage RSS to distribute flows across multiple CPU cores of multi-core platform. However, this is not enough to improve the throughput because the performance improvement gained by a multi-core processor depends heavily on the software algorithms and their implementation. For Netfilter, one reason for high overhead is that the lock of connection record table is contended by multi threads. In Quick NAT system, connection record table is built with lock-free hash table and shared among CPU cores. Based on compare-and-swap (CAS) atomic instruction, lock-free hash table eliminates the overhead of locks and makes it more efficient and scalable to share connection records on multicore server. 3.4 Polling and Zero-copy Packet Delivery In tradition, interrupts are used to notify the operation system when a packet is ready for processing. However, the interrupt handling is really expensive. When the rate of packet reception rises, the throughput of commodity servers may drop considerably in such systems [17]. To overcome this problem, we take advantage of Intel's DPDK to poll for data from NIC. The poll mode driver provided by DPDK allows end-host applications to access the RX and TX descriptors directly without interrupts, which eliminates overheads existing in interrupt-driven packet processing. Apart from using polling instead of interrupts, Quick NAT achieves full zero-copy to process the packets in user space. It manipulates the packet through pointers without copy operations in the process of NAT, increasing the throughput of packet processing. 4 Evaluation Quick NAT system achieves high-speed lookup for NAT rules by utilizing QNS algorithm and shares connection records among CPU cores efficiently. In this section, we evaluate Quick NAT with the following goals: ?Show the performance of Quick NAT compared with that of Linux Netfilter, ?Analyze the scalability of Quick NAT on the multicore commodity platform, ?Display the throughput of Quick NAT under different packet sizes, and ?Demonstrate Quick NAT's ability to search for NAT rules at high speed. 4.1 Experimental Set-up In our experiment, we use three Intel Core CPU i7-5930k @ 3.5GHz (6 cores) servers -- one for the Quick NAT system under test and another two acting as traffic generator and receiver -- each of which has an Intel 82599ES 10G Dual Port NICs and 16GB memory. Ubuntu 16.04 (kernel 4.4.0) and DPDK-16.11 are used. We use 8GB for huge pages according to Intel's performance reports. DPDK-based traffic generators are available, such as Wind River's DPDK-pktgen [18], which we use to generate traffic in line rate. 4.2 Experiment Topology The Figure 11 shows the experiment topology. There are three commodity servers. Quick NAT system is installed on server B. Server A and server C are used as the packet sending/receiving engines.
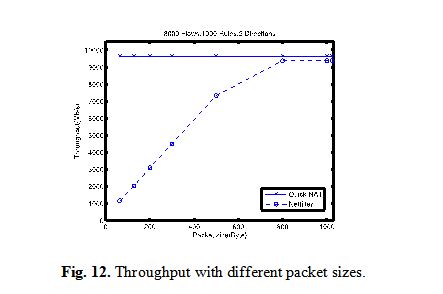
4.3 Results We perform a number of measurements to get an understand of throughput of Quick NAT and performance of QNS algorithm. 1)Throughput In this experiment, we add 1k rules into Quick NAT system at first and then set up 8k flows and change the size of packet to measure the performance of Quick NAT and Netfilter with different packet sizes. The result is shown in Figure 12. Quick NAT reaches close to line rate for minimized-sized packets, while Netfilter achieves only a fraction of line rate for small-sized packets and up to 9.3 Gb/s for packets larger than 800B.
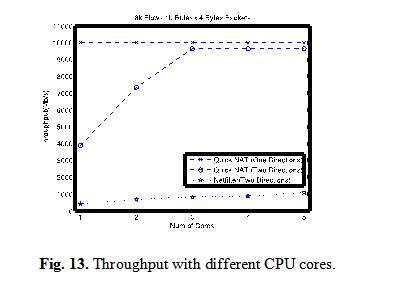
2)Scalability We add 1k rules and set up 8k flows with 64B packets. For this experiment, we change the number of CPU cores used by Quick NAT and Netfilter and record the throughput.
|