卿苏德《可信区块链评测结果通报》(3)
时间:2024-02-27 16:06 来源:网络整理 作者:墨客科技 点击:次
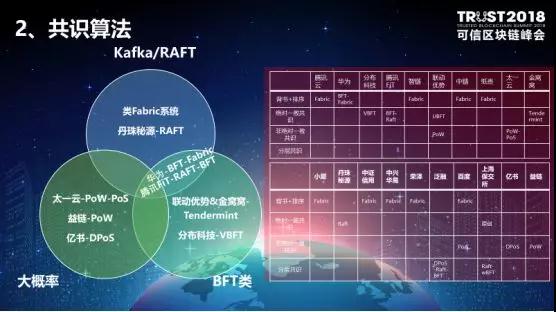
第二,共识算法方面,分为去信任的环境和信任的环境两大类。在Fabric类系统中,都是通过背书节点预运行,通过Kafka进行数据同步,最后通过排序节点进行统一处理,实现状态管理。在这种情况下,没有分叉的可能性,也没有交叉验证,但是存在脏数据,一旦涉及关联交易,不能并行处理,因此性能较差。另外,Fabric的容错率主要取决于背书策略的选取。 大概率一致共识算法,在部署前期存在冷启动的困境,要保证最开始的阶段不能让一个节点获得所有打包权限,实现的方案可能需要通过一些强制机制进行管理。 绝对一致性的共识,整个环境当中分为信任环境的 RAFT算法和非信任环境的BFT类算法,通过多个节点的消息交互、数据同步之后,保证数据的一致性。区别在于,RAFT只有两轮消息交互,无条件相信Leader。BFT类有三轮消息交互,对Leader发送的交易也会进行质疑。在这种情况下,更容易受到网络抖动、网络规模大小、出块策略等相关因素的影响。 让我们更加惊喜的是,分层共识和混合机制是一个很大的趋势。很多时候是许可链和非许可链、公有链和联盟链的融合。如果是ToC端的,你当然希望公有链能够获得更多的用户,如果对联盟链来说,ToB端的,你肯定希望各自之间会有一定的信任基础。目前,开放许可链、公有私有链都是业界探索的方向。例如,Algorand就是在PoS的基础上,通过随机选择算法(VRF),选择固定数量的节点进行PBFT共识,保证数据的一致性和防篡改、防抵赖特性。
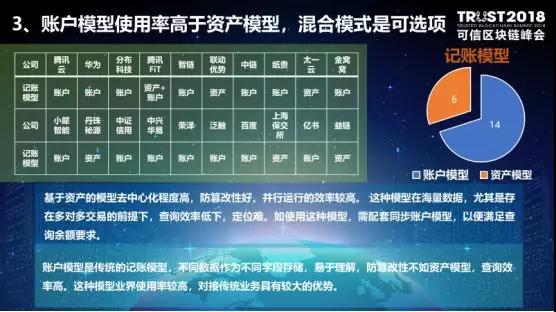
第三,账户模型方面,基于资产的模型,也就是UTXO,去中心化的程度很高,符合区块链理念,但是在海量数据存在情况下,查询的效率非常低,尤其在面对多对多交易时,定位能力差。基于账户的模型,方便查询余额和流水,可以更好地对接传统业务,方便理解。通过两种账户模式的混合来实现余额的查询和数据的防篡改是一种可行的思路。
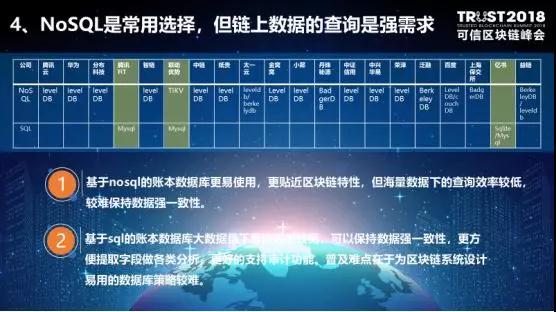
第四,账本数据库是储存账本数据的模块,在生产环境中更多使用非关系型的KV键值对数据库。在海量数据下,非关系型数据库高并发写入性能高,但查询效率较低,很难满足链上的数据查询和数据分析需求。这种情况下,Mysql等关系型数据库的查询能弥补查询效率的不足。因此有些厂商部署一条链,通过NoSQL进行实时存储,同时,又将数据同步存储在SQL数据库中,方便进行查询和数据分析。
第五,隐私保护,包括三个思路。 第一个是隔离,是通过多链、多通道以及分片实现,思路比较简单,实现较容易,隐私保护性好,代表公司像腾讯FiT是用多链技术,Fabric类用的是多通道。 第二是隐私保护算法相关的策略,包括同态加密、零知识证明等。同态加密,现在可以商用的是加法同态运算,用到乘法时占用空间太大,执行起来效果不是太理想。 第三是数据分类分级管理,通过多签名,通过权限管理,进行数据隐私保护的管控。
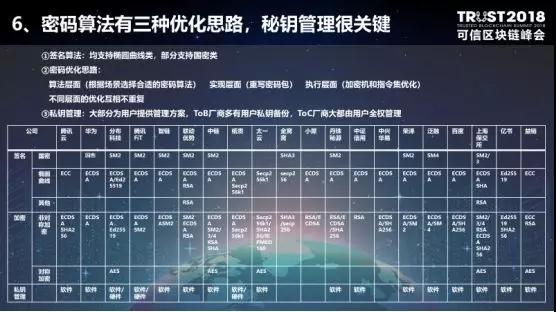
第六,密码算法有三种优化思路,密钥管理非常关键。 首先,由于现在的监管合规,尤其是金融领域,需要支持相关的国密算法,例如SM2,SM3,SM4等国密算法。国密算法的算法实现有优劣,这个值得各个厂商关注各类国密算法的性能问题。 其次,密码优化思路分为三层,三个层面的优化互不干扰。第一层是算法层面。现在的签名算法比较固定,大多都是基于椭圆曲线签名算法,可以通过不同的曲线来进行相关的调优。第二层是实现层面,例如腾讯FiT就派团队使用C++重写了密码包,提升了10-15%的算法性能。第三层是指令层面,例如泛融就委托Intel对指令集进行优化,进一步提升密码学算法的性能。 (责任编辑:admin) |