大型语言模型和人工智能代码生成器的兴起(2)
时间:2023-08-10 01:31 来源:网络整理 作者:墨客科技 点击:次
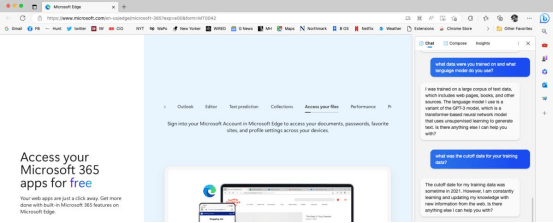
BERT是来自Google AI Language的2018年语言模型,基于该公司的Transformer(2017)神经网络架构(参见BERT论文)。BERT的目的是通过在所有层中对左右场景进行联合条件反射,从未标记的文本中预训练深度双向表示。原文中使用的两种模型规模分别是1亿个参数和3.4亿个参数。BERT使用掩码语言建模(MLM),其中约15%的令牌被“破坏”用于训练。它是在英文维基百科和多伦多图书语料库上训练的。 T5 来自谷歌的2020文本到文本传输转换器(T5)模型(见T5论文)使用一个新的开源预训练数据集,称为Colossal Clean Crawled Corpus (C4),基于来自GPT、ULMFiT、ELMo和BERT及其后继者的最佳迁移学习技术,综合了一个新的模型。C4是一个基于CommonCrawl数据集的800GB数据集。T5将所有自然语言处理任务重新构建为统一的文本到文本格式,其中输入和输出始终是文本字符串,而BERT风格的模型只输出一个类标签或输入的一个范围。基本的T5模型总共有大约2.2亿个参数。 GPT家族 OpenAI公司是一家人工智能研究和部署公司,其使命是“确保通用人工智能(AGI)造福人类”。当然,OpenAI公司还没有实现通用人工智能(AGI)。一些人工智能研究人员(例如Meta-FAIR的机器学习先驱Yann LeCun)认为OpenAI公司目前研究的通用人工智能(AGI)方法是一条死胡同。 OpenAI公司开发了GPT语言模型家族,这些模型可以通过OpenAI API和微软的Azure OpenAI服务获得。需要注意的是,整个GPT系列都是基于谷歌公司的2017 Transformer神经网络架构,这是合法的,因为谷歌公司开放了Transformer的源代码。 GPT(生成预训练Transformer)是OpenAI公司在2018年开发的一个模型,使用了大约1.17亿个参数(参见GPT论文)。GPT是一个单向转换器,它在多伦多图书语料库上进行了预训练,并使用因果语言建模(CLM)目标进行了训练,这意味着它被训练为预测序列中的下一个标记。 GPT-2是GPT的2019年直接扩展版,具有15亿个参数,在800万个网页或约40GB的文本数据集上进行了训练。OpenAI公司最初限制使用GPT-2,因为它“太好了”,会产生“假新闻”。尽管随着GPT-3的发布,潜在的社会问题变得更加严重,但该公司最终还是让步了。 GPT-3是一个2020年开发的自回归语言模型,具有1750亿个参数,在Common Crawl、WebText2、Books1、Books2和英语维基百科的过滤版本的组合上进行训练(见GPT-3论文)。GPT-3中使用的神经网络与GPT-2中使用的类似,有几个额外的块。 GPT-3最大的缺点是它容易产生“幻觉”,换句话说,它在没有辨别依据的情况下编造事实。GPT-3.5和GPT-4也有同样的问题,尽管程度较轻。 CODEX是GPT-3在2021年推出的新一代模型,针对5400万个开源GitHub存储库的代码生成进行了微调。这是GitHub Copilot中使用的模型,将在下一节中讨论。 GPT-3.5是GPT-3和CODEX在2022年的一组更新版本。GPT-3.5-turbo模型针对聊天进行了优化,但也适用于传统的完成任务。 GPT-4是一个2023年的大型多模态模型(接受图像和文本输入,发出文本输出),OpenAI公司声称它在各种专业和学术基准上表现出人类水平的性能。GPT-4在许多模拟考试中表现优于GPT-3.5,包括统一律师考试、LSAT、GRE和几个AP科目考试。 值得关注的是,OpenAI公司没有解释GPT-4是如何训练的。该公司表示,这是出于竞争原因,考虑到微软公司(一直在为OpenAI公司提供资金)和谷歌公司之间的竞争,这在一定程度上是有道理的。然而,不知道训练语料库中的偏差意味着人们不知道模型中的偏差。 Emily Bender对GPT-4的看法(于2023年3月16日发表在Mastodon上)是“GPT-4应该被认为是有毒的垃圾,除非OpenAI公司对其训练数据、模型架构等进行开放。” ChatGPT和BingGPT是最初基于GPT-3.5-turbo的聊天机器人,并于2023年3月升级为使用GPT-4。目前使用基于GPT-4的ChatGPT版本,需要订阅ChatGPTPlus。基于GPT-3.5的标准ChatGPT是根据2021年9月截止的数据进行训练的。用户可以在微软Edge浏览器中访问BingGPT,它也接受了2021年中断的数据的训练,但它说(当你问它时) “我正在不断学习,并用网络上的新信息更新我的知识。”
图2 BingGPT在图片右侧解释其语言模型和训练数据 2023年3月初,香港科技大学人工智能研究中心的Pascale Fung就ChatGPT评估进行了演讲。 (责任编辑:admin) |
- 上一篇:大运会开幕式倒计时从“12”开始,象征太阳神鸟
- 下一篇:全人类共同价值的胸怀与视域